
Früher oder später wird jeder der sich mit ecoDMS beschäftigt, Regex in Vorlagen von ecoDMS verwenden wollen. So ist zumindest mein Standpunkt, denn Regex bietet gegenüber der Klassischen Schlagwort-Erkennung einige Vorteile:
- Arbeiten mit Platzhaltern
- Ausschluss von bestimmten Kriterien
- Höhere Anpassbarkeit auf die eigenen Bedürfnisse
Viele haben aber leider immer noch Angst vor Regex, da es anfangs furchtbar kompliziert und komplex aussieht. Man muss aber Regex nicht vollständig beherrschen, um damit in seinen Vorlagen vom ecoDMS System zu arbeiten. Es reicht völlig aus, wenn man nur einen ganz kleinen Teil kann und das Prinzip verstanden hat. Ich werde in diesem Artikel versuchen, alles was man wirklich für ecoDMS braucht zu erklären, bildhaft darzustellen und noch ein, zwei Tipps zu geben.
Was ist Regex?
Laut Wikipedia: Ein regulärer Ausdruck (englischregular expression, Abkürzung RegExp oder Regex) ist in der theoretischen Informatik eine Zeichenkette, die der Beschreibung von Mengen von Zeichenketten mit Hilfe bestimmter syntaktischer Regeln dient.
In ganz einfachen Worten ist Regex also eine Filter-Sprache. Nichts anderes macht Regex nämlich, es filtert beispielsweise aus vorhandenen Texten, Wörter nach von uns vorgegebenen Kriterien heraus.
Was macht Regex in ecoDMS?
Nochmal ganz einfach geschildert, wozu wir Regex in ecoDMS benutzen wollen: Wir sagen ecoDMS mit Hilfe von Regex, dass es im Dokument nach bestimmten Wörtern, Zahlen, oder Zeichenketten suchen soll.
Klar, das geht auch mit der Schlagwort-Erkennung. Aber die Schlagwort-Erkennung bietet nicht die am Anfang genannten Vorteile von Regex!
Regex-Kriterien im Vorlagen-Designer als Kriterium angeben
Grundlegendes Schema
Regex wird im Vorlagen-Designer immer nach dem gleichen Schema angegeben, nämlich:
REGEX:b(HierKommenUnsereKriterienHin)bIn die beiden klammern können wir jetzt Regex-Platzhalter, aber auch normalen Text schreiben.
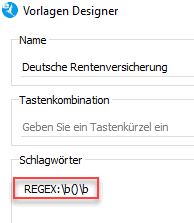
Schlagwörter
Wenn ihr also in einer Vorlage das Postfach 11 als Schlagwort angegeben habt, könnt ihr das in Regex einfach mit: REGEX:b(Postfach 11)b bewerkstelligen.
Der Effekt ist fast der selbe. Der einzige Unterschied ist der, dass jetzt Tatsächlich PostfachLEERZEILE11 im Dokument vorkommen muss. Wenn also im Dokument Postfach – 11 steht, würde die Vorlage nicht mehr erkannt werden.
Ausnahmen (Darf nicht im Dokument vorkommen)
Sollten wir aber !REGEX:b(Postfach 11)b schreiben, würde die Vorlage nicht erkannt werden, sobald Postfach 11 im Dokument vorkommt. Ist unter anderem sehr Praktisch für eine Klassifizierungsvorlage der Dokumentenart Information, da man so sicherstellen kann, das z.B. das Wort Rechnung nicht im Dokument vorkommt.
!REGEX:b(Rechnung)bOder
Mit dem | Operator könnten wir jetzt außerdem sicherstellen, dass noch ein paar andere Wörter nicht vorkommen dürfen.
!REGEX:b(Rechnung|Kontoauszug|Bescheid|Urkunde)bGesprochen würde das ganze jetzt so lauten: Es darf im Dokument nicht(!) Rechnung oder(|) Kontoauszug oder(|) Bescheid oder(|) Urkunde vorkommen.
Und
Wer sich jetzt fragt, wo ist der Und-Operator. Naja, den gibt es schon, brauchen wir aber nicht. Wir geben die beiden Regex Zeilen einfach nacheinander an (jede in eine neue Zeile)
REGEX:b(Postfach 11)b!REGEX:b(Rechnung|Kontoauszug|Bescheid|Urkunde)bCase Insensitiv
Regex ist normalerweise Case Sensitiv, also die Groß und Kleinschreibung wird beachtet. Wenn im Dokument beispielsweise RECHNUNG statt Rechnung steht, würden die Regex Kriterien von oben schon nicht mehr greifen.
Das können wir mit (?i) ändern. Wenn wir diesen Operator direkt nach den Doppelpunkten einfügen, wird die Groß- und Kleinschreibung nicht mehr beachtet. Könnte man natürlich auch für die Regex Zeile mit Postfach 11 machen, brauchen wir aber nicht unbedingt.
REGEX:b(Postfach 11)b!REGEX:(?i)b(Rechnung|Kontoauszug|Bescheid|Urkunde)bVorsicht bei Umlauten
Regex hat mit allen Umlauten, also mit ä Ä ö Ö ü Ü Probleme.
Diese können leider nicht direkt angegeben werden. Ich bin dazu übergegangen, statt des Umlautes immer .* zu schreiben. (Dazu mehr im nächsten Abschnitt)
Wildcards
Es gibt noch sogenannte Wildcards, also Platzhalter für bestimmte Zeichen. Ich erkläre erst kurz meine lieblings-wildcars für ecoDMS. Im Anschluss erkläre ich das gaze anhand eines Beispiels.
Die Besten Wildcards für ecodms
- .? steht für ein oder kein beliebiges Zeichen, außer einem Absatz. Sehr Praktisch für OCR-Fehler, da man so immer wieder falsch erkannte Buchstaben oder Zahlen in Wörtern oder Nummern trotzdem als Kriterium angeben kann.
- .* ist mit äußerster Vorsicht zu genießen. Es steht für beliebig viele oder ein Zeichen. Also auch wenn ein teil am Anfang und ein Teil am Ende des Dokumentes steht, wird es erkannt!
- [0?O?o] Null, großes oder kleines o Unglaublich praktisch für OCR-Fehler in Nummern!
Beispiele für die Anwendung der Wildcards
Ein neues Beispiel, vergesst also erstmal das obere Postfach 11 beispiel. Oder nein, vergesst es doch nicht 😉
Im Dokument steht also Postfach 11
Erkannt wird aber immer wieder etwas andres, beispielsweise:
Postfach11
Postfach 11
Postfach-11
Postfachi11
Dann geben wir einfach, statt REGEX:b(Postfach 11)b, folgende Regex Zeile an:
REGEX:b(Postfach.?11)bJetzt ist egal was erkannt wird, solange das Wort Postfach und die Zahl 11 nicht mehr als ein Zeichen weit voneinander getrennt sind, wirds erkannt!
Eigenen Regex-Kriterien testen und anwenden
Das war jetzt alles ziemlich viel Gelaber, also sage ich probiert es einfach selbst aus. Praxis ist immer besser als Theorie. Aber wie sollt ihr das jetzt ausprobieren, fragt ihr euch bestimmt. Ich gebe euch jetzt mal ein Praxisnahes beispiel, wie ich meine Regex-Kriterien in ecoDMS schreibe.
Vorlagen Designer sollte übrigens schon geöffnet sein 😎
Grundgerüst einfügen
Dann füge ich erstmal ein leeres „Regex-Grundgerüst“ in den Vorlagen-Designer ein.
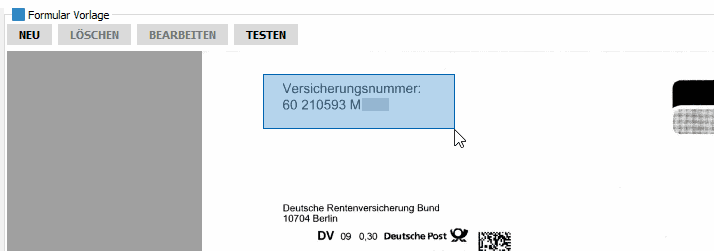
Text mittels OCR-Erkennung in die Zwischenablage kopieren
OCR-Text auf Regexstorm einfügen und testen
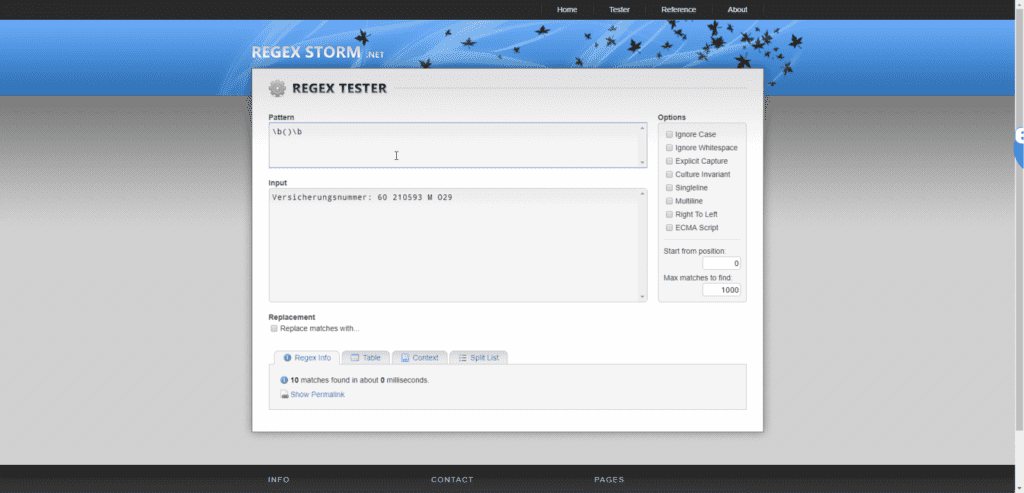
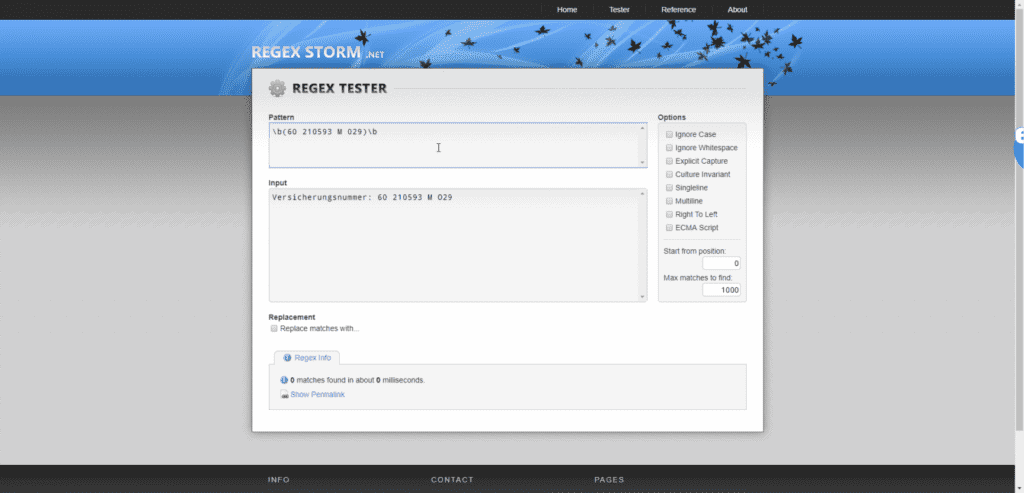
Das Problem ist hier der Abschnitt O29. Es handelt sich nämlich nicht um eine Null, sonder um ein großes o. Da ich die Regex-Kriterien oben manuell eingetippt habe, kann es eigentlich nur daran liegen. Außerdem wurde der Text im Kästchen Input ja bis zum M gelb hervorgehoben, und dann plötzlich nicht mehr.
Wir erinnern uns: REGEX:b()b gibt an, das alles in den Klammern und nicht nur teile dessen erkannt werden müssen!
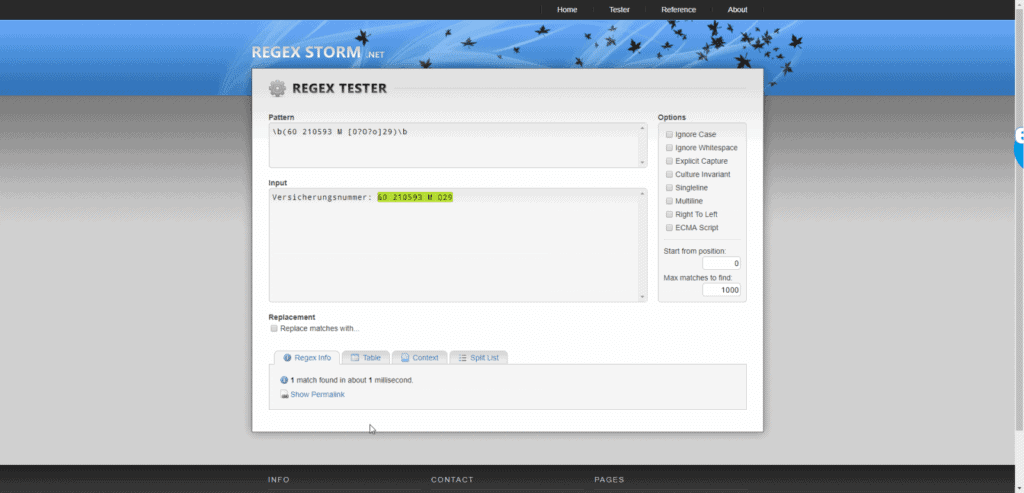
Mit Regexstorm experimentieren
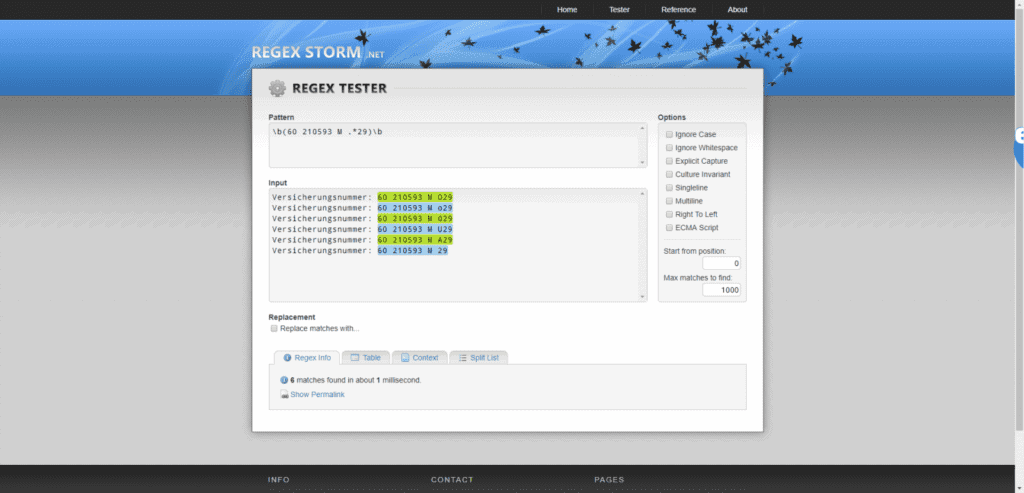
Erstelltes Regex Pattern in ecoDMS einfügen.
Nun das ganze noch kopieren und einfügen, fertig ist die Vorlage. (Genauer gesagt das erste Regex Kriterium der Vorlage, hier sollte man mindestens noch ein 2tes hinzufügen)
Kopieren
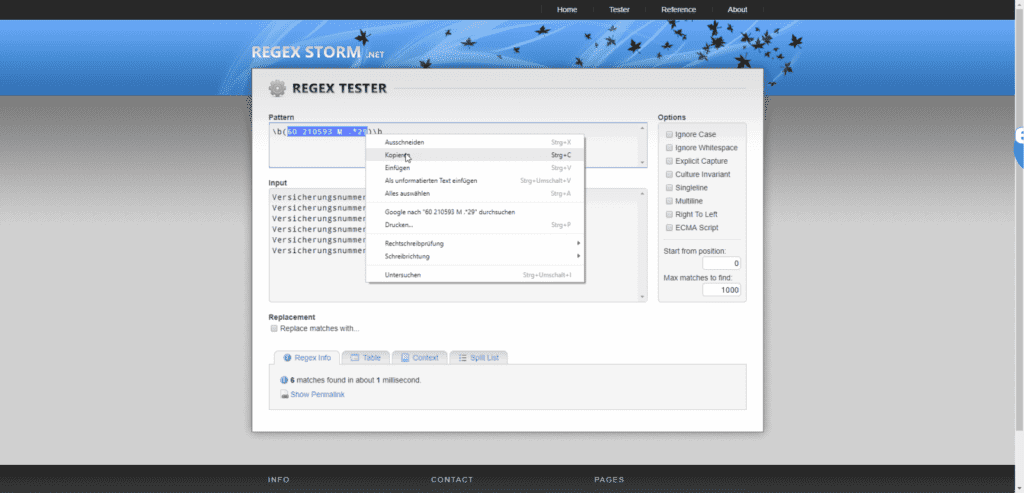
Einfügen
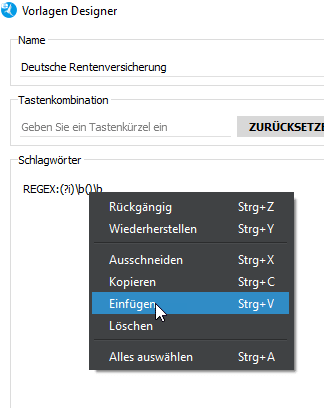
Und fertig ist die Vorlage. Sieht viel aus, aber wie bei allem anderen bleibt nur zu sagen, Übung macht den Meister. Ich brauche circa 5 Minuten um eine Dokumenten-Vorlage mit Regex Schlagwörtern / Kriterien zu erstellen. Nur den ganzen Weg darzustellen wie ich das machen, braucht leider etwas platz.
Regex-Snippets
Hier möchte ich euch die coolsten ecoDMS Regex Snippets von mir bereitstellen. (Fortsetzung folgt)
Regex Nettosumme (Deutsche Schreibweise der Zahlen)
Das Beispiel zu: „auslesen wenn nettosumme…“ gibts in der Hilfe bezüglich Regex bei ecoDMS.
Außerdem gibt es noch in den Kommentaren ein Beispiel, in dem der 2te Rechnungsbetrag zum Einlesen / Auslesen genutzt werden soll.
Schweizer Franken Betrag auslesen (Schweizer Variante der Zahlen)
Für schweizer Franken mit dem Tausender-Trennzeichen ‚ habe ich das Snippet aus der ecoDMS Doku mal leicht angepasst, damit es für diese Schreibweise der Zahlen funktioniert. Hier suche ich nach CHF im Text und die folgenden Zahlen werden ausgegeben mit maximal 2 Nachkommastellen (Punkt als Trennzeichen).
REGEX:(?<=CHF:)([s]*)((((d+)['.]{1,10})+d{0,2})|(d+(?!.)))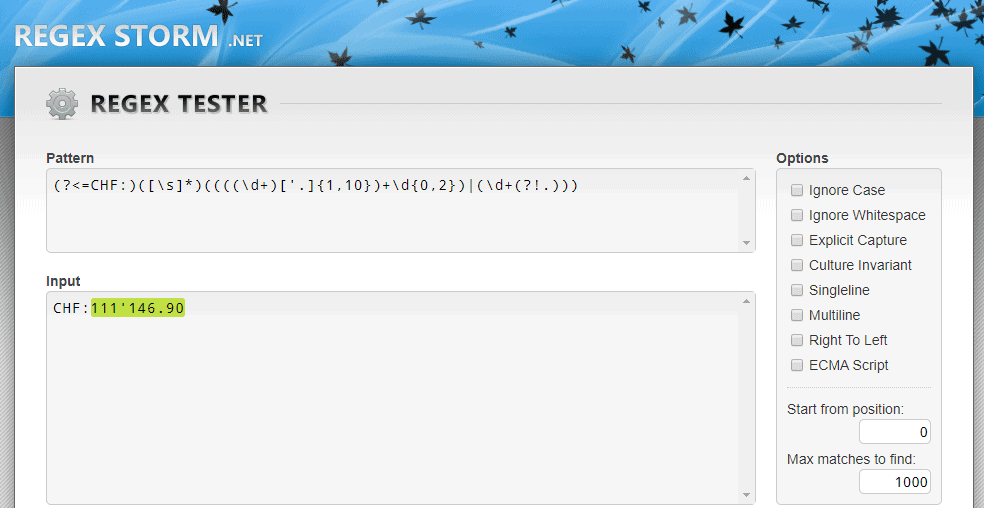
Habt ihr noch Fragen oder Ideen zu diesem Artikel? Schreibt es gerne in die Kommentare 😮





Hallo regex-Spezialisten, hallo Simon,
bin gerade am Verzweifeln.
Hier mein Problem:
In einer Vorlage gibt einen 2-zeiligen Text, aus dem ich nur ALLE Zeichen der 2. Zeile in die Klassifizierung übernehmen möchte.
Hier die 2 Zeilen
—–
Projekt
Neubau eines Gebäudes für Behinderte
—–
Also, mein Versuch:
REGEX:(?<=Projekt)([\s]*)([\S]*)
Damit bekomme ich "Neubau" . Wie muss das regex-Konstrukt sein, damit alle Zeichen von 'N' von Neubau bis einschließlich dem letzten 'e' von Behinderte gefunden werden.
Vilen dank schon mal.
Peter
Ich bräuchte einen Regex für folgendes Format: 18-OKT-2023 – kann mir da jemand helfen?
Wenn nicht schon selbst gelöst, hier einmal wie es funktionieren sollte: dd-MMM-yyyy
dd = Tag als Zahl mit vorangesteller Null 01 bis 31
d = Tag ohne führende 0 also 1 bis 31
Hallo Simon,
dank Deiner Ausführungen habe ich schon eine ganze Reihe von Belegen in der automatischen Klassifizierung. Beträge HINTER bestimmten Begriffen finde ich. Eine Aufgabe bekomme ich aber nicht gelöst: der Gesamtbetrag brutto steht irgendwo UNTER dem Wort Gesamtbetrag. Wie lese ich den Betrag aus?
Ich danke vorab für eine Lösung.
Hallo Simon,
ich bin ganz neu bei ecodms und regex und archiviere gerade Praxisrechnungen und Unterlagen. Dabei versuche diese Frage zu beantworten:
Ich möchte den Dateinamen der archivierten pdf-Datei in der Klassifizierungsvorlage als Klassifizierungsattribut auslesen. Kann ich das im Vorlagendesigner irgendwie als regex Befehl definieren? Oder geht das anders? Ich habe im Handbuch dazu nichts gefunden.
Hi Michael,
entschuldige die späte Antwort. Die Frage, wie man den Dateinamen in ecoDMS als Bemerkung verwendet, habe ich hier schon einmal beantwortet 🙂
Ich hoffe, das hilft dir weiter und beste Grüße
Hi Michael,
ich habe den mir einzig bekannten Weg bereits hier beschrieben.
Wie auch immer, da die Frage ja so häufig auftritt, habe ich nun mal ein Ticket bei ecoDMS aufgemacht. Mal schauen, ob die uns helfen möchten 😀
Hallo Simon,
gibt es die Möglichkeit ein Datum per Regex Befehl berechnen zu lassen? Mir geht es um Zahlungszielen auf Rechnungen. Also Rechnungsdatum zahlbar in 14 Tagen etc. Hätte dann gern ein Feld wo ich erkennen kann wann ich das zu bezahlen hab. Gruß Jens
Hi Jens,
entschuldige die späte Antwort. Ich denke, nicht, dass das funktioniert, da Regex ja zur Mustererkennung und nicht zur Berechnung (Rechnungsdatum + 14 Tage) dient.
Beste Grüße
Hallo Simon,
ich habe Deine oben gezeigte Version zum Auslesen von Schweizer Franken bei mir ausprobiert. Da funktioniert leider etwas nicht! Ich habe dann ein wenig weiter gesucht und folgendes gefunden, was dann auch in Regex Storm funktioniert hat.
REGEX:(?<=CHF:)([\s]*)((((\d+)[‚.]{1,10})+\d{0,2})|(\d+(?!.)))
Leider hat es in ecoDMS auch nicht so richtig funktioniert. Ich habe dann versucht ein wenig anzupassen. Ob das richtig ist weiss ich nicht, es funktioniert jedenfalls ein wenig besser.
REGEX:(?<=CHF:)([\s]*)((((\d+)[‚.´’]{1,10})+\d{0,2})|(\d+(?!.)))
Das Klassifizierungsattribut „Rechungsbetrag“ ist ein Numerisches Feld und OCR gibt Zeichen statt Zahlen zurück. Somit wird da nichts eingetragen. Wenn ich jetzt das REGEX auf ein Feld wie Bemerkungen (Textfeld) anwende funktioniert es bestens!
Aktuell habe ich ein neues Klassifizierungsattribut als „Freies Textfeld“ Namens Rechnungsbetrag erstellt und verwende das so!
Vielleicht hast du ja noch eine bessere Idee, dann bin ich um diesen Vorschlag sehr dankbar.
Jedenfalls Danke für Deine Arbeit!
Dieter
Hey Simon!
Bin gerade auch am Experimentieren mit REGEX.
Und mich würde interessieren, ob mein Vorhaben möglich ist.
Für die Bemerkung lasse ich den Kopf prüfen und suche nach „Ihre Rechnung“ und eine Zeitspanne, das funktioniert super.
REGEX:(?<=)(Ihre Rechnung) REGEX:([\s]*)\d{2}([\.]\d{2})([\.]\d{4})( - )([\s]*)\d{2}([\.]\d{2})([\.]\d{4})Würde gerne noch vorne dran noch den Anbieter der Rechnung haben, dies lässt sich leider nicht zuverlässig auslesen, kann ich diesen auch als Fixwert eintragen lassen?
Und z.B. zwischen den REGEX ein “ – “ einfügen?
„Anbiater“
Vielen Dank!
Schönes Wochenende und bleib gesund.
Beste Grüße
Spohky
Guten Tag Simon.
Ich hätte da eine Frage zu Regex. Ich versuche verzweifelt einen Betrag mit Leerzeichen auszulesen.
Beispiel in Rechnung: 5 000.00 Euro.
Jetzt wird im DMS aber nur die Zahl 5 geschrieben und nicht 5000.00
Was muss ich eintragen damit dieses Leerzeichen ignoriert wird?
Meine Standard Formel im DMS: REGEX:([\s]*)((((\d+)[`´,.]{1,10})+\d{0,2})|(\d+(?!,)))
Besten Dank für dein Feedback und Gute Arbeit die du leistest.
Gruss Max
Hey Max,
so was in der Richtung sollte funktionieren:
^[+-]?[0-9\s]{1,3}(?:,?[0-9]{3})*\.[0-9]{2}$https://regex101.com/r/j5Oh8H/1
Hilft dir das weiter? 😀
Beste Grüße
Simon
Hallo Max
Hast du eine Lösung gefunden? Ich scheitere in ecoDMS am gleichen Punkt, beim Auslesen des nachfolgenden Betrages, getrennt durch ein Leerzeichen:
1 550.90
Hat jemand dafür den richtigen REGEX Befehl, bitte? Das wäre toll! Vielen Dank.
Gruss
Sebi
Noch eine Ergänzung zu meinem gestrigen Eintrag:
Ausgehend von dem von ecoDMS vorgegebenen REGEX-Wert (siehe nachfolgend), der mir nur den Wert „1“ ausliest:
Wie muss die Anpassung / Ergänzung dieser REGEX aussehen, damit es mir effektiv 1 550.90 ausliest?
REGEX:([\s]*)((((\d+)[‚`‘,.]{1,10})+\d{0,2})|(\d+(?!,))) = ERGEBNIS: 1
Moin Moin,
sehr tolle Seite hier. Bin auf der Suche nach der Lösung eines meiner Probleme hier gelandet.
Vielleicht hat jemand von euch eine Lösung für mein Problem im petto:
Wir bekommen Rechnungen von diversem Hersteller, wo die Gesamtrechnungssumme aus den Dokumenten ausgelesen werden soll. Leider ist es so, dass der eine Hersteller als Bezeichnung Gesamtsumme benutzt, wo hinter jedem Buchstaben ein Leerzeichen ist. Dies verhindert das Auslesen per RegEx, da immer jeder Buchstabe im Dokument durchsucht wird und nicht das Wort Gesamtsumme. Habt ihr da eine Lösung parat?
Danke für eure Hilfe 😉
Hi Sven,
danke für deinen Kommentar 🙂
so was in der Art könnte passen: https://regex101.com/r/3If11E/1
Beste Grüße
Simon
Moin Simon,
moin Forumgemeinde,
gibt es eine Möglichkeit bspw. im Bemerkungsfeld eine Kombination aus festen Begriffen und Variablen zu verwenden?
Ich bekomme zum Beispiel einen Kontoauszug und möchte folgendes in der Bemerkung stehen haben:
„Kontoauszug – Geldinstitut – 03/2021“
Hierbei wäre „Kontoauszug – Geldinstitut – “ ein fester Begriff und lediglich „03/2021“ über RegEx angefügt.
Geht so etwas?
Wie wäre der Aufbau?
Ein anderes Beispiel könnte sein:
Rechnung: %RG-Nr.% – Datum: %Datum% – Betrag: %Betrag%
Also ebenfalls ein Mix aus Begriffen und Variablen.
Ich freue mich über jedwede Anregung 🙂
Viele Grüße aus dem hohen Norden
Heiko
Hi Heiko,
danke für deine Frage! In Programmiersprachen geht sowas mit Replace… Aber leider ist Regex nur eine Abfragesprache und eignet sich nur bedingt zum manipulieren. Steht dazu inzwischen vielleicht was in der Anleitung von ecoDMS? (Hab da schon länger nicht mehr reingeschaut :D)
Beste Grüße
Simon
Tolle Beträge und Hilfen… Ich habe so langsam ein Ahnung… aber…
gibt es eine Möglichkeit
12. Januar 2021 in
12.01.2021
zu wandeln?
Hi Michael,
also, theoretisch ist das möglich. Aber ich würde mal Vermuten, dass man hier ein paar Stunden investieren müsste, um sich das ganze anzueignen. Ich habe dafür leider kein fertiges Regex herumliegen.
Aber normalerweise sollte ecoDMS in den Vorlagen auch ausgeschriebene Monate als Datum erkennen, hat das bei dir nicht geklappt?
Beste Grüße
Simon
Hallo Simon,
toller Artikel. Ich habe eine funktionierende Regex – Partitur.
REGEX:(?<=Name[\s])([\d\S])+
REGEX:(?<=Rechnung[\s])([\d\.][\S])+
REGEX:(?<=Datum,[\s])([\d\.])+
Nun wird das Datum im Format 14.01.2021 ausgegeben.
Wir benötigen für die Bennenung aber das Datum ohne Punkt im Format 14012021
Geht das irgendwie?
Für Hilfe wäre ich sehr Dankbar.
Sonnige Grüße
R
Hallo Simon,
bin begeistert von Deinen ecoDMS-Seiten. Da findet man ja relativ wenig im Netz 😉
Aktuell bin ich nun auch in der Regex-Hölle angekommen und versuch mein ecodms zu optimieren.
Aktuell stehe ich vor einem Problemchen, bei dem ich völlig ahnungslos bin und nicht mehr weiterkomme.
Deshalb hab ich die Hoffnung, dass Du mir nen kleinen Tip hast 🙂
Ich habe folgenden Text :
Von: Max Mustermann
An: Test Tester
Ich möchte nun den Teil nach dem „Von:“ auslesen, was mit einem Lookbehind mit (?m)(?<=Von:)([\s]*)\b(.*)
auch ganz gut in https://regex101.com/ funktionierte
In ecoDMS nimmt er aber immer den kompletten Text incl. dem "An:…..", was vermutlich daran liegt, dass ecoDMS die Zeilenumbrüche nicht im OCR hat 🙁 )
Mein nächster versuch war dann nur den Text innerhalb der "“ rauszufiltern, was auch mit (?:<)[^) im regex101 klappt.
In ecoDMS bekommt er jedoch als Ergebniss nur die „“ 🙁
Hast Du mir irgendeinen Tip wie ich das hinbekomme ?
Vielen Dank schonmal und viele Grüße
Dirk
Hallo Simon,
ich habe es selber herausgefunden und möchte es hier auch für alle Interessierten zur Verfügung stellen.
Abweichungen zu meiner Fragestellung :
Mir liegen viele emails vor die als PDF ausgedruckt wurden, diese beginnen alle mit
Von: Max Mustermann
An: Test Tester
Thema : Blablablab
ecodms zieht sich nun den kompletten Text ohne Zeilenumbrüche, sodass man mit diesen nicht arbeiten kann.
Ich prüfe nun mit einem „Lookbehind“ auf „Von:“ und lese bis zum ersten „>“
REGEX:(?m)(?)
LG
Dirk
Hi Dirk,
danke, dass du die Lösung gepostet hast. Sehr nett von dir 😎
Beste Grüße
Simon
Hi,
irgendwie hat sich bei meinem letzten Post der regex verabschiedet, da steht nur noch (?) 🙁
Also, um im ecodms folgendes zu erkennen :
An: Max Mustermann
klappt es mit diesem regex : REGEX:(?m)(?<=An:)(\s)([)
Grüße
Hallo Simon,
ich habe in ecoDMS das Problem, das ecoDMS manchmal Zeilenbasiert und manchmal Spaltenbasiert einliest. Folgende Rexex wird verwendet: (?<=Gesamtbetrag)\s*(\d{0,3}\.{0,1}\d{1,3},\d{2})
Beispiel:
Summe 123,90€
zuzüglich 90,25€
Gesamtbetrag 1.002,20€
In Dokument A ergibt die Regex: 1.002,20, wie erwartet in Dokument B 123,90. Leider häufen sich die Beispiel B's. Liest man den Text via Strg+ rechte Maustaste aus dem Dokument z.B. in das Bemerkungsfeld, sieht man das ecoDMS teilweise zeilenbasiert arbeitet und teilweise spaltenbasiert. Leider find ich keine Logik, wann welches Verhalten zutrifft, daher ist es schwer algemeingültige REGEX zu bauen.
Kennt jemand das Problem und hat auch schon eine Lösung?
Viele Grüße
Marcus
Hallo Marcus,
hast Du für dieses Problem eine Lösung gefunden?
Viele Grüße
Jan
Hallo Jan,
nein, leider habe ich noch keine Lösung gefunden, aber noch mehr Probleme, z.B. das geänderte Vorlagen nicht bei der automatischen Erkennung genutzt werden, sehr wohl aber wenn man die Erkennung neu anstößt…
Und ein Update von 18 auf 21 funktioniert nicht, das anscheinend die Postgres DB nicht sauber hochgezogen wird… Leider bekomme ich da nur den Hinweis einen Supportvertrag abzuschließen, wobei das wohl eher als BUG einzustufen ist, da das Postgres Problem Branchenweit existiert und auf Grund falscher Client-Kommunikation entsteht.
Viele Grüße
Habt ihr inzwischen eine Lösung für dieses Problem?
Mir geht es total auf den Wecker, wenn er mal zeilenweise und dann spaltenweise einliest.
Ich kann so keine Vorlagen sinnvoll erstellen
Kann man mit Regex erzwingen immer nur eine Zeile auszulesen, oder ist das ein OCR Problem?
Grüße
Robert
Hallo Zusammen,
ich stolpere in ecoDMS immer wieder über folgendes Problem:
Textbeispiel:
Summe 123,90€
zuzüglich 90,25€
Gesamtbetrag 1.002,20€
Ausgelesen werden soll der Gesamtbetrag, also 1.002,20€. Folgendes Regex habe ich verwendet: REGEX:(?<=Gesamtbetrag)\s*(\d{0,3}\.{0,1}\d{1,3},\d{2})$
Das funktioneirt im Regex.Storm Tester wunderbar, auch in anderen Programmeirsprachen nur leider in ecoDMS nicht. Der Grund ist, das ecoDMS den Text wohl nicht zeilenweise auswertet sondern die linke Spalte einliest und dann die rechte (bzw. es überhaupt als Spalten betrachtet wird). Somit kommt der Wert 123,90 bei der Regexabfrage raus, was natürlich nonsens ist. Liest man den Text aus ecoDMS mit Strg + rechter Maustaste ein, sieht man den gleichen effekt, zuerst die linke Spalte dann die Rechte.
Im Fließtext funktioniert die Regex einwandfrei.
Hat dazu jemand einen Tipp?
BG Marcus
Hallo Simon,
danke für deinen tollen Beitrag. Ich habe auch einige Befehle integriert aber ich scheiter an 2 Stellen und hoffe du kannst mir helfen:
1. Ich habe den Fall, dass das Wort „Rechnungsendbetrag“ zwar von ecodms erkannt wird, aber an der falschen Stelle. Es gibt nämlich vorher das Wort „Netto-Rechnungsendbetrag“ und dadurch liest ecodms immer die Nettosumme und nicht die Bruttosumme ein. Hast du einen Tipp, wie ich die Summe nach dem letzten „Rechnungsendbetrag“ auslesen kann?
2. Hast du einen Schnipsel für das englische Datumsformat? Ich habe einen Lieferanten, der das Datum so angibt: May 9, 2020.
Vielen Dank für deine Tipps und deine Hilfe.
Grüße
Thomas
Ich habe auch gleich noch eine weitere Frage: Ich suche nach dem Betrag auf dem Dokument nach dem Wort „Betrag (EUR)“ mit den Klammern um das Wort EUR herum. Das führt natürlich dazu, dass im ecodms das nicht mehr erkannt wird. Man kann auch nicht einfach mit \bBetrag (EUR)\b nach dem exakten Ausdruck suchen. Das führt bei mir zu nichts. Hast du da einen Tipp?
Hey Thomas,
danke für deine Frage. Scheinbar hast du 2 Probleme:
\b makriert in Regex Wort-Grenzen, das geht aber glaube ich nicht mit leerzeichen
Sonderzeichen wie klammern müssen via \ escaped werden (Damit regex erkennt dass du wirklich das Klammerzeichen meinst, und kein Kommando der Regex-Sprache)
Das hier sollte funktionieren:
\bBetrag\b.\(EUR\)
Ich hoffe das hilft dir weiter 🙂
Beste Grüße
Simon
Hey Thomas,
danke für deine Frage und das Lob des Artikels 🙂
1.: Hier würde ich mit dem „Nicht“ Befehl von Regex arbeiten: (?
2.: Leider nein, habe dafür nichts fertiges, aber dieser Beitrag auf Stackoverflow sieht vielversprechend aus.
Ich hoffe das hilft dir weiter
LG
Simon
Hi Simon,
bin über diese Frage gestolpert, ich glaube, ich habe den selben Lieferanten wie Thomas 🙂
Leider funktioniert das Negieren von „Netto“ nicht. Auch nicht im Tester.
Hast Du event. noch einen Tipp für mich? Bin hier langsam am verzweifeln …
Hallo.
Ich habe leider gar keine Erfahrung mit REGEX. Trotzdem möchte ich und muss ich mich beruflich damit auseinander setzen.
Ich suche und belese mich nun schon seit einigen Monaten zu diesem Thema, jedoch ohne viel Erfolg.
Ich benötige REGEX um Steuerbescheide zu klassifizieren.
Es wäre schon ein riesen Schritt wenn ich mit REGEX die Steuernummer auslesen könnte. Da hier die / Zeichen für mich eine riesen Hürde darstellt.
Ist dies den überhaupt machbar oder sollte ich einen anderen Weg gehen?
Ich hoffe mir kann jemand helfen.
Hey Moni,
danke für deine Frage und wilkommen in der Regex-Hölle (nur ein kleiner Spaß) 😉
Also, ich denke das auslesen von Steuernummern sollte klappen. So als ersten entwurf (für eine Bayrische Steuernummer), habe ich das hier geschrieben:
[0-9]{3}\/[0-9]{3}\/[0-9]{5}
Den aufbau von Steuernummern habe ich auf Wikipedia gefunden. Je nach dem, was du prüfen willst, müsste man das Regex noch etwas erweitern. Dann sollte es das schon gewesen sein 🙂
LG
Simon
Hallo,
sehr schöne Erklärung. Vielleicht kannst du mir helfen.
Ich habe immer Probleme wenn ich mehrere Zeichen in einer Zeile habe wo ich nur das Ende haben möchte.
Beispiel:
Summe [1] EUR 13,66
Wenn ich das ganze in Regex101 mache, habe ich in der ersten Gruppe meinen Wert 13,66.
(?i)(?<=SUMME)\s*.[0-9][0-9]?.\s*\w*\s*(\d?\.?\d?\d?\d[,|.]?\d\d)
Wenn ich das ganze in Regex Storm mache auch aber der sagt mit das der String Teil ([1] EUR 6,10) ist. Und ich glaube das ist das Problem, der Stringteil muss 13,66 sein, damit ecoDMS es erkennt, liege ich da richtig?
Wenn ja, wie kriege ich das hin?
Hey Dominik,
danke für dein Kommentar und sorry für die verspätete Antwort.
Wenn ich dich richtig verstehe, möchtest du nur den letzten Teil des Strings haben. Dafür gibt es in Regex $. Hier gibts ne ziemlich gute erklärung, aber leider auf englisch.
Das hier sollte für dein Beispiel funktionieren (einmal mit und einmal ohne EUR, falls jemand ein Beispiel braucht):
Ich hoffe das hilft dir weiter 🙂
LG
Simon
Hi Jan
Wäre toll wenn du den Regex teilen könntest. Habe immer das Problem, dass Daten auf Berichten sind im Format 3. Januar 2020, mit einem Leerzeichen nach dem Tag. Dies erkennt EcoDMS leider nicht, sehr nervig.
Vielleicht hat jemand eine Lösung
Nachdem Jan seine Lösung hier ja leider nicht präsentiert, ist meine hier:
REGEX:\b(\d+)(.?(\s?))(?i:Jan(?:uar)?|Feb(?:ruar)?|Mär(?:z)?|Mar|Mrz|Apr(?:il)?|Mai|Jun(?:i)?|Jul(?:i)?|Aug(?:ust)?|Sep(?:tember)?|Okt(?:ober)?|Nov(?:ember)?|Dez(?:ember)?|[2-9]|1[0-2])(.?(\s?))((?:19[0-9]\d|2\d{3})(?=\D|$))\b
Das in der Vorlage bei Datum unter „Optionen“ eintragen und ecoDMS sollte jedes Datum erkenne. Insbesondere aber die mit Leerzeichen drin.
Ist doch gar nicht so lang 😉
Gruß
Mark
Ich hab das auch bei dem Datumsfeld probiert – leider wird das bei mir nicht automatisch gefüllt, obwohl es Regexstorm passt und bei Eintragen in das Bemerkungsfeld ebenfalls richtig ist. Gibts dazu noch eine Idee?
Format ist: 5. Mai 2021
Gruß Martin
Hey Martin, hast du einen Link zu deinem Regex oder das ganze Snippet?
Beste Grüße
Hi Simon, ich hab einfach per C&P das Regex von Mark übernommen. VG Martin
Im Bemerkungsfeld funktioniert das auch wunderbar. Nur im Datumsfeld nicht.
Hallo,
Danke für den Beitrag. Das hat mich schon viel weitergebracht.
An einer Stelle tu ich mir gerade echt schwer.
Ich hab eine Textstelle: 123456DEB123456
Ich will mit RegEx alles rechts von dem DEB haben
und einmal alles links von dem DEB haben.
(das muss ich dann 2x machen soweit ist mir das klar)
Aber ich schaff es nicht, dass er mir das abscheidet.
Bitte um Hilfe
schöne Grüße
Thomas
Hi Thomas,
ich denke, dass hier wäre ein gute Ausgangspunkt (kann man bestimmt noch verbessern) ?
(?<=DEB)[^DEB]*|[^DEB]*(?=DEB)
https://regex101.com/r/ylKPrJ/1
LG
Hallo,
meine Frage ist, wie kann ich eine Zahl mit führenden Nullen ergänzen? Habe bei comdirect die Finanzreports, die mit Nr. 1 bis Nr. 12 nummeriert werden.
Ich würde gern im Bemerkungsfeld „Finanzreport Nr. 02“ statt „Finanzreport Nr. 2“ stehen haben.
Ich bekomme es irgendwie nicht hin. (Bin zu doof für RegEx)
Gruß Daniel
Hallo Daniel,
leider habe ich dafür kein Regex in Petto.
Ich vermute mal, das ganze müsste mit Gruppen und untergruppen funktionieren.
Ich bitte um verständnis dafür, dass ich nicht für jeden individualisiertes Regex erstellen kann. Falls ich mal vor dem selben Problem stehe, werde ich den Code natürlich teilen. Aber aktuell habe ich leider wenig zeit zum „rumprobieren“.
LG
Simon
Vielen Dank.
Ich habe nun einige Tage lang müßig recherchiert und herumexperimentiert, um eine Lösung dafür zu finden, per REGEX das im eingescannten Beleg stehende Belegdatum auslesen zu lassen.
Diese Anleitungen hier waren dabei eine gute Hilfe !!! Zumal ich bislang so überhaupt keine wirkliche Ahnung hatte, wie das funktioniert.
Falls Interesse daran besteht, über EcoDMS das Belegdatum in allen erdenklichen Formaten (TT.MM.JJJJ, TT. MMMM JJJJ, TT-MM-JJJJ usw.) auslesen und in die Klassifizierung zurückgeben zu lassen, kann ich die REGEX gerne hierüber bereitstellen.
Ist nur recht … lang, funktioniert aber bislang bei mir einwandfrei.
Vermutlich geht das Ganze auch etwas übersichtlicher, aber ich habe keine Ahnung davon, habe es ausgetüftelt und … es funktioniert halt und ich kann das Original-Belegdatum direkt in der Belegübersicht sehen.
Mehr brauche ich nicht 😀
Hallo Jan,
erstmal vielen Dank für dein Feedback. Es freut mich natürlich zu hören, dass dir der Artikel bei deinem ecoDMS-Regex-Abenteuer geholfen hat ;).
Es würde mich (und ich denke auch alle anderen) sehr freuen, wenn du das Regex hier als Kommentar posten möchtest ?
Als alternative, kannst du es mir auch gerne per E-Mail an simon@simon42.com schicken. Dann werde ich es gerne in den Beitrag einbauen 🙂
Liebe Grüße und bleibt gesund
Simon
Hallo Simon, Hallo Jan,
ich bin schon lange auf der Suche nach einem ordentlichen RegEx für das Belegdatum.
Leider bin ich, trotz Recherchen und dieser super Anleitung, wohl nicht nicht in der Lage so was sebst zu erstellen. Ihr würdet mir einen sehr großen Gefallen tun, wenn Ihr mir einen funktionierenden Eintrag freudlicherweise zukommen lassen würdet. Viele Grüße Chris
Hi Chris,

für’s Belegdatum habe ich bisher meistens auf „Individuelle“ Lösungen für jede Vorlage gesetzt, wie z.B. „dd.MM.yyyy“, hier zu sehen:
Ich würde mich auch sehr über den Code freuen 😉
LG
Simon
REGEX:(?<=Datum[\s])([\d\.])+
Hi
Ich suche genau nach dieser Möglichkeit. Wäre super, wenn Du den Regex Term mit uns teilen könntest. Lieben Dank und Gruss
Michi
Hallo Jan
Ich würde mich auch sehr darüber freuen.
Habe häufig das Problem, dass das Datum in folgendem Format steht:
3. September 2020
Huhu – das wäre doch super wenn du den Code Posten könntest.
Oder sogar per mail an info@torambo.com schicken könntest.
Vielen Dank.
Hallo Jan,
bitte teile die REGEX doch mit uns. Wir sind alle sehr gespannt und DU würdest vielen damit helfen!
Vielen Dank!
Mark
Mit Regex beschäftige ich mich auch gerade. Tolle Anleitung als Basis!
Was ich noch brauche ist eine Formel um einen Betrag auszulesen der nicht direkt hinter dem Wort Betrag kommt sondern erst ein paar Stellen weiter.
zb. Betrag 100,00 150,00
Dort soll die 150,00 ausgelesen werden.
Gruß Marco
Hi Marco und danke für das ausführliche Feedback ?
Zu deiner Frage:
Ich denke da an eine Abwandlung, so ähnlich wie im CHF beispiel: [REGEX:(?<=CHF:)([\s]*)((((\d+)['.]{1,10})+\d{0,2})|(\d+(?!.)))]
Die frage ist nur, ob das einfach überspringen der ersten Treffer-Gruppe der Richtige weg ist…
Aber funktionieren würde das hier denke ich:
REGEX:(?<=Betrag:)(([\s]*)\d{1,8}([\.,]\d{2})){2}
So ist das 2te Vorkommen die Regex Gruppe 1, sollte klappen 🙂
Super geil 😀
Man sucht echt vergeblich wenn es um solche Themen geht.
Vielen Dank
Danke für die netten Worte Robert ?